
Surfactants are widely applied in industry as detergents, foaming agents or dispersants, amongst others. In particular, they play a critical role in the personal and home care segment. Market studies predict a growth of the global production to over 16 million tons by 2022 corresponding to an annual revenue of around 40 billion US-dollars. Companies face not only business competition, but also increasingly more stringent regulations regarding environmental compatibility, toxicity, and sustainability. For product design and development, machine learning-based techniques can be exploited for virtual screening and prediction of key properties, like the critical micelle concentration. In this way, raw material costs and development time can be reduced by focusing experimental testing on the most promising candidates.
The Challenge
A key property of surfactants is the critical micelle concentration (CMC). It is the concentration when the surface tension does no longer change upon addition of more surface-active agents. Predicting the value of this concentration, at the design phase of a product is critical since it allows to determine virtually the quantity of a surfactant required to control the tension of a liquid. In this case study, we used the MAPS QSPR module to develop a correlative model for predicting the CMC of anionic surfactants. This class of surfactants represent currently the largest group of surfactants.
The Work
A data set comprising 60 sulfate and sulfonate surfactants with known CMC was used as basis for developing a correlative model. The structures of these surfactants were built, and their geometry was optimized using MAPS building tools. Molecular descriptors, i.e. chemical and physical molecular information transformed into useful numbers for statistical modeling, were calculated using the MAPS Descriptors plugin. MAPS QSPR module was used to generate QSPR models using a genetic algorithm (GA)-based search. The best performing models were validated using training/test set approach.
Figure 1. Representative surfactant molecule from data set.
The Results
We have developed a correlative model for predicting the critical micelle concentration of anionic surfactants. A correlation between the CMC and the shape of the molecule, expressed as a topological descriptor, and the constitution of the molecule, expressed in form of a van der Waals volume-based descriptor, was identified. The final model shows a high accuracy in terms of R2 and RMSE statistics.
This correlative model is ideally suited to be used in MAPS screening and innovation workflow environment. The workflow does not only allow to efficiently screen large compound libraries but can be also used to create systematically a multitude of virtual variant structures of a base scaffold. This represents an efficient strategy for identifying suitable candidates or potential replacements, since experimental work can be focused on the most promising compounds which ultimately saves development cost.
Applying machine learning-based techniques is, however, not limited to any specific type of material nor to a specific property but can be applied to any material and property of interest.
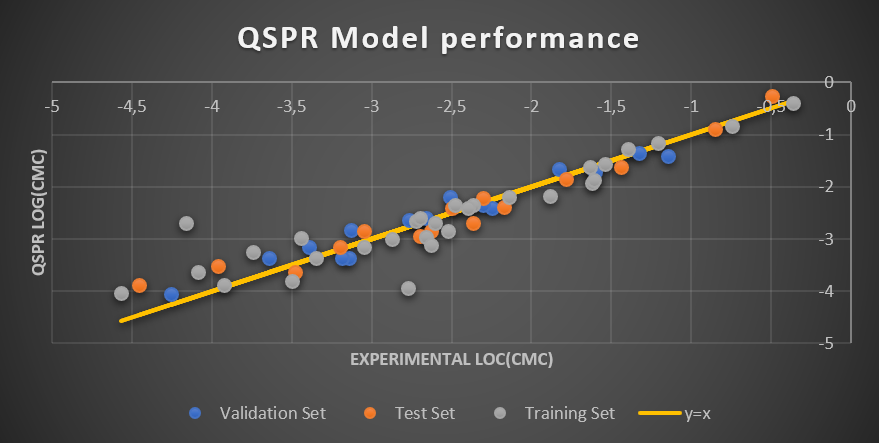
Figure 2: Representation of the QSPR log(CMC) as a function of the experimental one for the validation (orange), test (green) and training (purple) sets. For comparison, y=x reference is plotted.